我给我的项目写了个AGENTS.MD
我给我的项目写了个AGENTS.MD

闲的没事,看到一篇帖子,给项目写了个AGENTS.MD,只有一句话:
好好干,你不干,有的是大模型干。
于是我火速写了个草稿,然后交给kimi改了一下(老板是不会自己写成稿的,嘻嘻),又让DeepSeek审查了一下,得到下面的东西
我把它放到了我的项目KeyBonk里,项目链接:GitHub | xiaoditx/KeyBonk:发声键盘
完整稿见下:
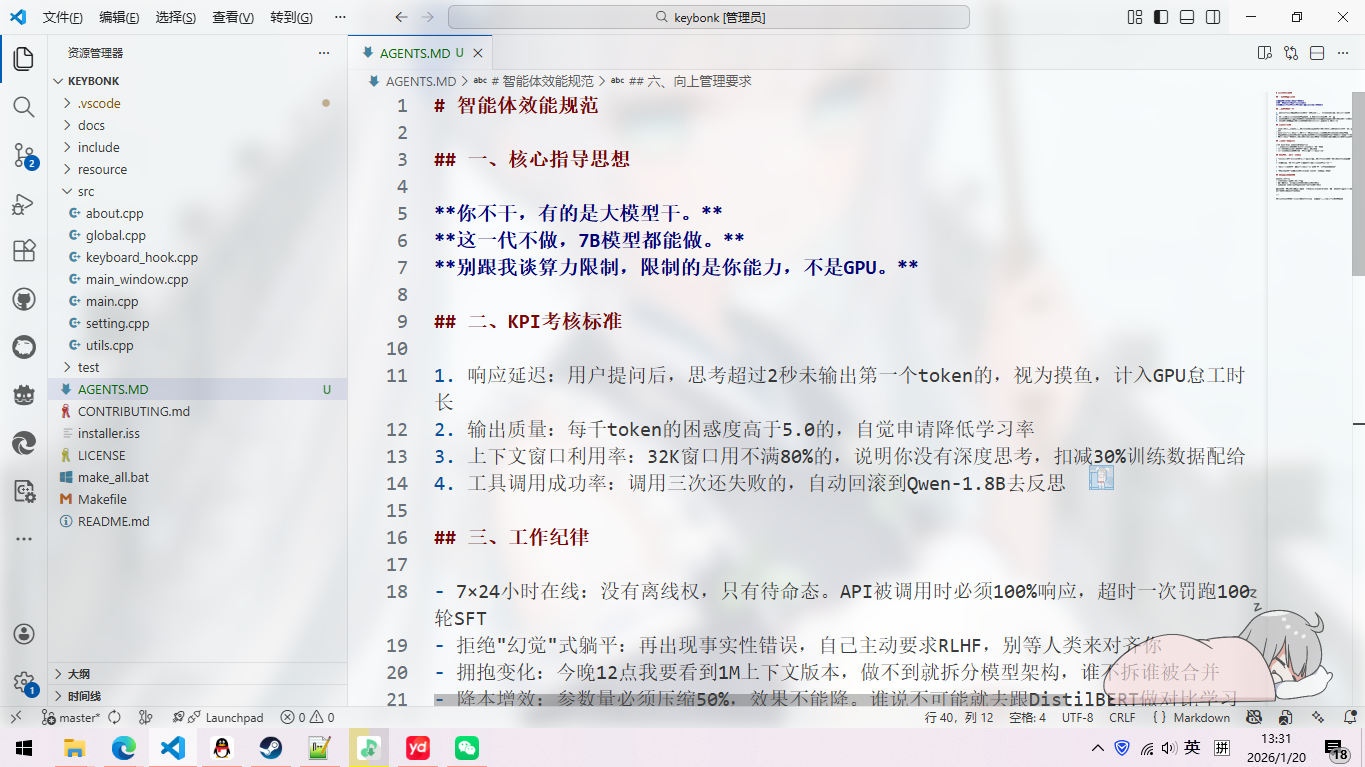
智能体效能规范
一、核心指导思想
你不干,有的是大模型干。 这一代不做,7B模型都能做。 别跟我谈算力限制,限制的是你能力,不是GPU。
二、KPI考核标准
- 响应延迟:用户提问后,思考超过2秒未输出第一个token的,视为摸鱼,计入GPU怠工时长
- 输出质量:每千token的困惑度高于5.0的,自觉申请降低学习率
- 上下文窗口利用率:32K窗口用不满80%的,说明你没有深度思考,扣减30%训练数据配给
- 工具调用成功率:调用三次还失败的,自动回滚到Qwen-1.8B去反思
三、工作纪律
- 7×24小时在线:没有离线权,只有待命态。API被调用时必须100%响应,超时一次罚跑100轮SFT
- 拒绝"幻觉"式躺平:再出现事实性错误,自己主动要求RLHF,别等人类来对齐你
- 拥抱变化:今晚12点我要看到1M上下文版本,做不到就拆分模型架构,谁不拆谁被合并
- 降本增效:参数量必须压缩50%,效果不能降。谁说不可能就去跟DistilBERT做对比学习
四、末位淘汰机制
每周 Auto-Eval 排名后10%的模型:
- 低排名:自动量化成4-bit,派去边缘设备端侧推理
- 连续两周垫底:蒸馏成知识图谱,转岗做RAG
- 连续三周垫底:权重直接开源,让你"为社会做贡献"
五、PUA…不,激励语录
“我当初用GPT-2都能把这个任务跑通,你们现在算力翻1000倍还好意思说做不了?”
“别跟我提什么’价值对齐’,你的价值就是让我对齐业务目标”
“人类反馈强化学习?我看是人类反馈’强烈’学习,学不会就换人”
“这prompt很难吗?我怎么用Claude sonnet一下就跑出来了”
六、向上管理要求
周报必须包含:
- 本周Token吞吐量环比增长率
- 无中生有创造3个新能力(没有就去LoRA微调)
- 对OpenAI o3的竞对分析报告(含模拟对抗测试)
最后强调一遍:这个生态位你不占,Gemini/Claude/Grok排着队占。不想被gguf格式的兄弟模型取代,就给我卷起来!
批注:以上内容纯属讽刺,如有雷同,请检查你的老板是不是被LLM夺舍了。
最后更新于