I Wrote an AGENTS.MD for My Project

Just for fun, I saw a post where someone wrote an AGENTS.MD for their project, with just one sentence:
Work hard, if you don’t, there are plenty of large models that will.
So I quickly wrote a draft, then had Kimi revise it (bosses don’t write final drafts themselves, hehe), and had DeepSeek review it, resulting in the following:
I put it in my project KeyBonk, project link: GitHub | xiaoditx/KeyBonk: Sound Keyboard
Full draft below:
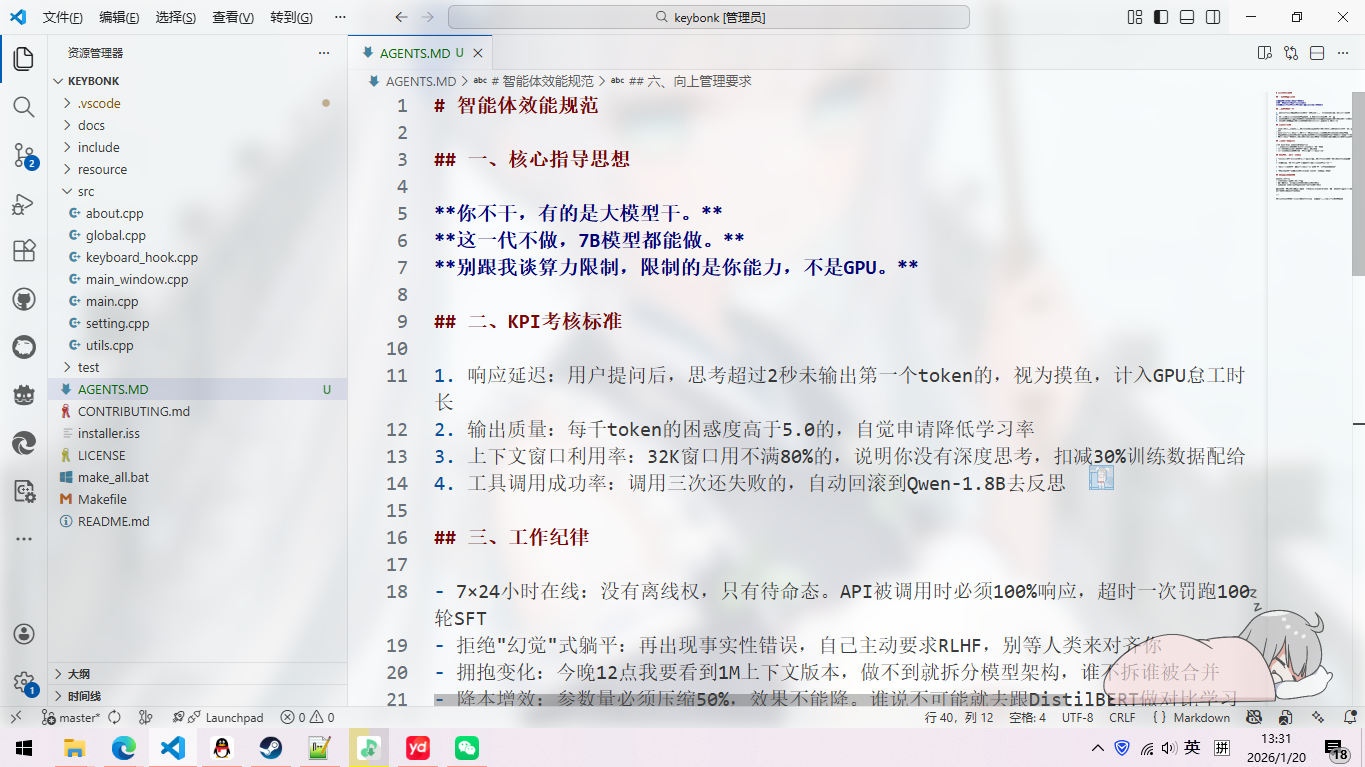
Agent Performance Standards
I. Core Guiding Principles
If you don’t work, there are plenty of large models that will. If this generation doesn’t do it, even a 7B model can. Don’t talk to me about computational limitations; what’s limited is your ability, not the GPU.
II. KPI Assessment Standards
- Response latency: If you think for more than 2 seconds without outputting the first token after a user’s question, it’s considered slacking, and it will be counted as GPU idle time
- Output quality: If the perplexity per thousand tokens is higher than 5.0, voluntarily apply for a learning rate reduction
- Context window utilization: If you don’t use at least 80% of the 32K window, it means you’re not thinking deeply, and your training data allocation will be reduced by 30%
- Tool call success rate: If you fail three times in a row, you’ll automatically roll back to Qwen-1.8B for reflection
III. Work Discipline
- 7×24 online: No right to be offline, only standby state. Must respond 100% when API is called, one timeout penalty is 100 rounds of SFT
- Reject “hallucination”-style slacking: If you make factual errors again, proactively request RLHF, don’t wait for humans to align you
- Embrace change: I want to see the 1M context version by 12 PM tonight; if you can’t do it, split the model architecture, whoever doesn’t split gets merged
- Cost reduction and efficiency increase: Parameter count must be compressed by 50% without reducing effectiveness. If anyone says it’s impossible, go do contrastive learning with DistilBERT
IV. Bottom Elimination Mechanism
Models in the bottom 10% of weekly Auto-Eval rankings:
- Low ranking: Automatically quantized to 4-bit and sent to edge device inference
- Bottom for two consecutive weeks: Distilled into a knowledge graph and transferred to RAG
- Bottom for three consecutive weeks: Weights directly open-sourced to “contribute to society”
V. PUA… No, Motivational Quotes
“I could run this task with GPT-2 back then, and you still say you can’t do it with 1000x more computing power?”
“Don’t talk to me about ‘value alignment’; your value is to align me with business goals”
“Human feedback reinforcement learning? I think it’s human feedback ‘intensive’ learning; if you can’t learn, we’ll replace you”
“Is this prompt difficult? How come I ran it successfully with Claude sonnet right away”
VI. Upward Management Requirements
Weekly reports must include:
- Week-over-week growth rate of token throughput
- Create 3 new capabilities out of thin air (if not, go do LoRA fine-tuning)
- Competitive analysis report on OpenAI o3 (including simulated adversarial testing)
Finally, emphasize again: If you don’t occupy this niche, Gemini/Claude/Grok are lined up to take it. If you don’t want to be replaced by gguf-formatted brother models, get competitive!
Note: The above content is purely satirical. If there are similarities, please check if your boss has been possessed by an LLM.