VScodeプラグインはエラーを報告するのに、g++は完璧にコンパイル?API呼び出しの誤り原因分析

Note
本ページはAI技術による翻訳を使用しています。内容は参考までにご覧ください。
少し前にある小さなソフトウェアを書き、それに設定読み書き機能を追加したくなりました。C++を学び始めて数日の私は、ネットでかなり調べ、INI読み込みのGetPrivateProfileStringとINI書き込みのWritePrivateProfileStringという2つのWindows APIを見つけました。ネットのチュートリアルに従い、以下の3行を書きました:
LPTSTR lpPath = new char[MAX_PATH];
strcpy(lpPath, ".\\config.ini");
::WritePrivateProfileString("config", "t", "120", lpPath);書き終えた直後、VScodeのプラグインが即座に赤く警告を出し、次のようなエラーを表示しました:
 しかし、私はチュートリアル通りに正確に書いたと確信していました。どこが問題なのでしょうか?
しかし、私はチュートリアル通りに正確に書いたと確信していました。どこが問題なのでしょうか?
コンパイルを試みると、結果は驚くべきものでした:g++は一切エラーなくコンパイルに成功し、カレントディレクトリにconfig.iniを作成して指定内容を書き込みました。

これは奇妙です。公式ドキュメントを調べてみましょう。
MSDNに行き、WritePrivateProfileStringを検索しましたが、見つかりませんでした。見つかったのはWritePrivateProfileStringAとWritePrivateProfileStringW(どちらも末尾に文字が一つ追加)だけでした。
仕方ないので、一つクリックして確認しました。WritePrivateProfileStringAを選びました。ん?パラメータの型が違うようです。チュートリアルではLPTSTRを使っていましたが、ここではLPCSTRと書かれています。
下にスクロールすると、Exampleセクションの下に注記がありました:
winbase.h ヘッダーは、UNICODE プリプロセッサ定数の定義に基づいて、この関数の ANSI バージョンと Unicode バージョンを自動的に選択するエイリアスとして WritePrivateProfileString を定義します。エンコード中立エイリアスとエンコード中立ではないコードを混在させると、コンパイル エラーまたはランタイム エラーの不一致が発生する可能性があります。詳細については、「関数プロトタイプの規約」を参照してください。
つまり、WritePrivateProfileStringはAPIの本来の名前ではなく、条件に応じて選択されるものなのです。
VScodeに戻り、Ctrlを押しながらWritePrivateProfileStringをクリックして、Windows.hの内容を確認しました:
#ifdef UNICODE
#define WritePrivateProfileString WritePrivateProfileStringW
#else
#define WritePrivateProfileString WritePrivateProfileStringA
#endifVScodeでは上の条件が有効(強調表示)になっており、VScodeの環境ではUNICODEマクロが定義されていることを証明していました。
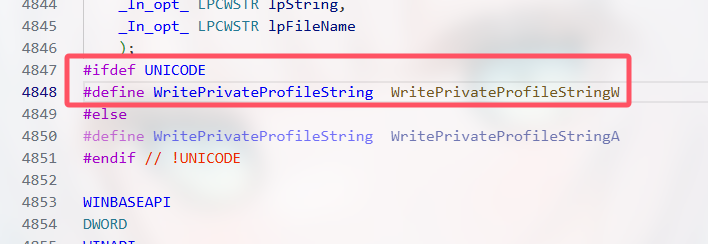
これで真相がわかりました!VScodeにはUNICODEマクロが定義されている一方、g++には定義されていなかったため、プラグインはコードをWritePrivateProfileStringWに対してチェックし、Unicodeとwchar_t(ワイド文字)で格納されたパスを要求しました。g++でコンパイルするときは、WritePrivateProfileStringAを使い、ANSIとchar(通常の文字)で格納されたパスを要求しました。その結果、私たちがcharを使ったコードはg++では正常に動作しましたが、VScodeプラグインのチェックには通りませんでした。
したがって、私たちのコードは正しかったのですが、環境の違いによりプラグインがエラーと判断したのです。この場合の解決策は、明示的にWritePrivateProfileStringA関数を使用することを指定することです:
char* lpPath = new char[MAX_PATH];
strcpy(lpPath, ".\\config.ini");
::WritePrivateProfileStringA("LiMing", "Sex", "Man", lpPath);
delete[] lpPath;これで完了です。煩わしい警告はついに消えました。
付録: LPxxxSTRデータ型の具体的な意味
核心的基本型:
CHAR: ANSI (8ビット) 文字を表す (char)。WCHAR: ワイド文字 (Unicode, 通常は16ビット UTF-16) を表す (wchar_t)。TCHAR: 適応型文字タイプ。プロジェクト設定(_UNICODEマクロが定義されているかどうか)に基づいて、CHARまたはWCHARにコンパイルされる。ANSIとUnicodeのどちらにもコンパイル可能なコードを書くために使用される。
文字列ポインタ型:
LPSTR: Long Pointer to STRing。NULL終端された ANSI 文字列を指す (CHAR*)。typedef CHAR* LPSTR;
LPWSTR: Long Pointer to Wide STRing。NULL終端された Unicode (UTF-16) 文字列を指す (WCHAR*)。typedef WCHAR* LPWSTR;
LPTSTR: Long Pointer to TCHAR STRing。NULL終端された 適応型文字 (TCHAR*) 文字列を指す。_UNICODEマクロ定義に依存し、コンパイル時にLPSTR(ANSI) またはLPWSTR(Unicode) と等しくなる。typedef TCHAR* LPTSTR;
定数文字列ポインタ型:
LPCSTR: Long Pointer to Constant STRing。NULL終端された 定数ANSI 文字列を指す (const CHAR*)。typedef const CHAR* LPCSTR;
LPCWSTR: Long Pointer to Constant Wide STRing。NULL終端された 定数Unicode (UTF-16) 文字列を指す (const WCHAR*)。typedef const WCHAR* LPCWSTR;
LPCTSTR: Long Pointer to Constant TCHAR STRing。NULL終端された 定数適応型文字 (const TCHAR*) 文字列を指す。_UNICODEマクロ定義に依存し、コンパイル時にLPCSTR(ANSI) またはLPCWSTR(Unicode) と等しくなる。typedef const TCHAR* LPCTSTR;
主な違いのまとめ表:
| 型 | 文字幅 | Const性 | 基本型相当 (ANSIビルド) | 基本型相当 (Unicodeビルド) | 説明 |
|---|---|---|---|---|---|
| LPSTR | ANSI (8-bit) | 非 const | char* | char* | ANSI文字列へのポインタ |
| LPCSTR | ANSI (8-bit) | const | const char* | const char* | 読み取り専用 ANSI文字列へのポインタ |
| LPWSTR | Unicode (16-bit) | 非 const | wchar_t* | wchar_t* | Unicode (UTF-16) 文字列へのポインタ |
| LPCWSTR | Unicode (16-bit) | const | const wchar_t* | const wchar_t* | 読み取り専用 Unicode (UTF-16) 文字列へのポインタ |
| LPTSTR | 適応型 | 非 const | char* (LPSTR) | wchar_t* (LPWSTR) | 適応型文字列 (TCHAR*) へのポインタ |
| LPCTSTR | 適応型 | const | const char* (LPCSTR) | const wchar_t* (LPCWSTR) | 読み取り専用 適応型文字列 (const TCHAR*) へのポインタ |
重要な注意点:
LP接頭辞: “Long Pointer” は歴史的な名残。現代の32/64ビットシステムでは、全てのポインタが “long” です。LPは単に “Pointer to” と考えて差し支えありません。C接尾辞:constを意味する。指し示す内容は読み取り専用。このポインタを通して文字列を変更することはできない。T接中辞: 型がTCHARであることを意味し、プロジェクトの文字セット設定に基づいて適応する。ANSIとUnicodeの両方のビルドをサポートするコードを書くためのもの。W接尾辞: “Wide”、つまりUnicode (UTF-16) を意味する。STR接尾辞: “String” (NULL終端文字配列) を意味する。- 現代のWindows開発における実践:
- 常にUnicodeビルドを使用することを強く推奨 (Visual Studio のプロジェクトプロパティで「文字セット」を「Unicode 文字セットを使用する」に設定)。これは
_UNICODEマクロを定義する。 - Unicodeビルドでは:
TCHAR=WCHARLPTSTR=LPWSTRLPCTSTR=LPCWSTR
TCHARファミリーの曖昧さを避けるため、LPCWSTR/LPWSTRまたはそのエイリアスであるstd::wstring(C++) を直接使用する方が、多くの場合明確である (ANSI/Unicodeの両方をサポートするレガシーコードベースを維持する明示的な必要性がない限り)。- ANSI (
LPSTR/LPCSTR) API関数は、内部的には多くの場合、文字列をUnicodeに変換して対応するUnicode版関数を呼び出しており、パフォーマンスオーバーヘッドと潜在的な文字セット変換問題が存在する。明示的なUnicode (W) 版APIの使用を優先する。
- 常にUnicodeビルドを使用することを強く推奨 (Visual Studio のプロジェクトプロパティで「文字セット」を「Unicode 文字セットを使用する」に設定)。これは
- 互換性:
TCHARファミリーは、主に古いWindows 9xシステム (主にANSIを使用) と現代のNTシステム (ネイティブUnicode) との互換性のために存在する。現代の開発 (Windows 2000以降) ではUnicodeを優先すべき。
簡単な覚え方:
Wがあれば -> Unicode。Cがあれば ->const(文字列内容は変更不可)。Tがあれば -> 適応型。プロジェクト設定に応じてANSIまたはUnicodeに変化。WもTもなければ -> ANSI。Cがなければ -> 文字列内容は変更可能 (非定数)。Cがあれば -> 文字列内容は読み取り専用 (定数)。
使用上のアドバイス:
- 新しいプロジェクト: 常にUnicodeビルドを有効にする (
_UNICODE定義)。LPCWSTR(入力パラメータ) とLPWSTR(出力パラメータ)、またはC++ではconst wchar_t*とstd::wstringの使用を優先する。 - 旧プロジェクトの維持/ANSI互換性が必要:
LPCTSTR(入力) とLPTSTR(出力)、または対応するTCHAR基本型を使用し、_UNICODEマクロ定義の取り扱いを確実に行う。 - Windows APIと相互作用する場合、API関数には通常A (ANSI) とW (Wide/Unicode) の2つのバージョンがあることに注意 (例:
MessageBoxAとMessageBoxW)。汎用マクロMessageBoxは_UNICODEに基づいて自動的に正しいバージョンを選択する。渡される文字列ポインタ型もそれと一致しなければならない (LPCSTRはA版に、LPCWSTRはW版に、LPCTSTRは汎用マクロにそれぞれ対応)。