研究性学習総合報告書
Note
本ページはAI技術による翻訳を使用しています。内容は参考までにご覧ください。
編著:xiaoditx
校閲:馬赫陽
〇. 序文
コンピュータ技術は様々なプログラミング言語なしには成り立ちません。したがって、プログラミング言語の発展は、コンピュータ技術の発展を側面から反映していると言えます。プログラミング言語の各進化は、時代のコンピュータ技術に対する要求を証言しており、プログラミング言語の発展史は、コンピュータ技術の発展史そのものだと言えるでしょう。
本研究性学習報告書は、「プログラミング言語」の歴史から着手し、各時代における異なる言語の特徴を分析し、コンピュータ技術の発展過程を覗き見ようと試みます。同時に、どのようにして自分に適したプログラミング言語を選択するかを分析することも目的としています。
本文の基本構成は以下の通りです:
- プログラミング言語の先史的な原型
- 機械語とアセンブリ言語
- 高級言語の進化経路
- 現代プログラミング言語の多次元的発展
- プログラミング言語の発展法則と選択に関する提案
一. プログラミング言語の誕生
人類は怠惰であり、昔からそうでした。後漢時代、ジャカード織機と呼ばれるものが広く利用されました。この装置は商代まで遡ることができ、その機能から、それが置かれた時代とはほとんど相容れないものでした:
紋様式ジャカード織機は後漢に出現し、花楼とも呼ばれました。それは線製の花本(紋様 pattern chain)で提花プログラムを保存し、衢線( harness cords)で経糸を引き上げ開口(shed)を作りました。花本は提花機上に紋様情報を保存する一連のプログラムであり、紋様の要求に従って経線を代表する脚子線(lingzi threads)と緯線を代表する耳子線(erzi threads)で編成されました。
客観的物体を利用してプログラムを記録し労力を節約するという点で、ジャカード織機は、後漢の時代に、時代を先取りした種を静かに埋めました。シルクロードが開通すると、ジャカード織機はヨーロッパに流入し、何世代もの工人、物理学者、数学者の手によって、次第に根を下ろし発芽し、「コンピュータ技術」という大木に成長しました。
二. 第一世代プログラミング言語——機械語
人類と機械の初めての「対話」は、機械語によって行われました。これは純粋な0と1だけで構成される「言語」であり、これが定義上の第一世代コンピュータ言語です。
0と1の世界は、コンピュータの最も根底にある「本質」です。したがって、十分に基本的で、十分に複雑であり、記述効率も比較的低くなります。以下に、機械語コードの短い例を示します。感じ取ってみてください。
2進数表現:
10001011 01000101 00000100
01011011
10001001 11000011
16進数表現:
8b 45 04
5b
89 c30と1の混在により、コードの内容が識別しにくいことが明らかにわかります。したがって、人間が所謂筋肉記憶のようなもので素早く認識することは非常に困難です。
実際、上記の長い文字列は、簡単な加算演算さえ支えるには不十分です。もし今、誤って一文字書き間違えたら:
誤り:
10001011 01000101 00000100
01011011
10001101 11000011
正解:
10001011 01000101 00000100
01011011
10001001 11000011どちらが間違っているか一目でわかる人はいるでしょうか?おそらくいないでしょう。機械語で加算を実装するには少なくとも3行必要です。たった3行以内でさえ、誤り修正の難しさがこれほど高いのですから、実際のソフトウェア開発に使用する際の困難は想像に難くありません。
これが機械語の長所と短所を引き起こします:
長所は以下の通りです:
- 最も低水準に近く、実行速度が十分に速い
- 機械が直接認識して実行でき、補助プログラムが不要
- 余計な無駄な内容が出現しない(プログラムサイズが小さい)
短所は以下の通りです:
- 記憶难度が大きい
- 低水準を直視するため、学習難易度が高い
- 機械への依存性が強く、一種類の機械に対して一種類の構造であり、移植が困難
- 0と1のみであるため、誤りを書きやすく、誤り修正も困難
王爽氏の『アセンブリ言語』における以下の記述を思わず思い出します:
機械語プログラムの書取りと読取りは簡単な仕事ではなく、すべての抽象的な2進コードを覚えなければならない。上記は非常に単純な小さなプログラムであるが、機械語の晦渋難解さと誤り確認の難しさを暴露している。こんなに小さなプログラムを書くのでさえこうなのだから、実際に役立つプログラムは少なくとも数十行の機械語が必要だとすると、状況はどうなるだろうか?
三. アセンブリ言語:プログラマーたちの自然言語への最初の追及
機械語がそんなに書きにくいなら、どうすればいいのでしょうか?プログラマーたちは考えました:機械と直接「会話」するのが少し困難なら、翻訳者を見つければいいのではないか?こうしてアセンブリ言語が誕生しました。
百度百科はアセンブリ言語を次のように定義しています:
アセンブリ言語(Assembly Language)は、電子計算機、マイクロプロセッサ、マイクロコントローラ、またはその他のプログラミング可能なデバイスのための任何一种の低水準言語であり、記号言語とも呼ばれる。
簡単に言えば、アセンブリ言語は万能の通訳者のようなものです。この「通訳者」は一種の言語を制定しました。あなたが任意の機械と「対話」する必要があるときは、この「通訳者」を見つけ、その制定した言語を話せば、状況に応じて異なる表現で機械に伝えてくれます。
例えば、機械Aは0000を加算演算と規定し、機械Bは1010を加算演算と規定します。この時、アセンブリ言語は加算演算を+であると規定します。そうすれば、私たちがプログラムを書くときは+と書くだけでいいのです。アセンブリ言語は機械Aに対しては0000を伝え、機械Bに対しては1010を伝えます。
アセンブリ言語のこの「人によって異なる」翻訳により、機械語の機械への強い依存性の問題が一定程度解決されました。同時に、0000を+に変えるような操作を通じて、プログラムの作成がより直感的になり、記憶しやすくなりました(1 0000 2と1+2、どちらが覚えやすく書きやすいでしょうか?これは明らかです)。
したがって、アセンブリ言語は時に記憶を補助するテキストという意味で、ニーモニック(助記符)とも呼ばれます。以下の定義を参照してください:
ニーモニック(mnemonic)は、人々の記憶を容易にし、命令の機能と命令オペランドを記述できる記号である。ニーモニックは、命令機能を示す英語の単語またはその略語である。
アセンブリの導入により、記憶はもはや退屈で理解しにくいものではなくなりました。例えば、MOV、ADD、CALLなどの命令があり、少しでも英語の基礎があれば十分に理解でき、2進数よりも速く記憶できるようになります。
異なる設計の機械間には無視できない違いがあることを考慮し、アセンブリもIBM PCアセンブリ、ARMアセンブリ、GNU ASM、MASM、NASMなど、さまざまなバージョンが派生してきました。ここでは詳細には触れません。
ここで、アセンブリ言語に関するある記事の評価を引用します:
アセンブリ言語の出現は、プログラマーを煩雑な2進数プログラミングから解放し、プログラムの論理と機能実装により集中できるようになり、コンピュータソフトウェアの発展に重要な基礎を築いた。
要するに、アセンブリ言語は人々に「その然(ぜん)を知って其の所以(ゆえん)を知らず」の状態に到達させます。コンピュータ技術の学習において、これはほとんどの場合実際には良い状態です。なぜなら、これにより煩雑な低水準の原理から解放され、コンピュータで問題を解決したいとき、機械の低水準アーキテクチャがどうなっているかをまず見るのではなく、どのようなアルゴリズムを使うかを直接考えられるようになるからです。
tips:筆者はアセンブリ言語が非常に好きです。それは低水準に近く、コンピュータ科学の基礎への扉を開く鍵です。これは非常に挑戦的な言語であり、ソフトウェアの動作原理を最も学べる言語です。
四. 高級言語の夜明け:C/C++の革命
1. C言語の誕生
1972年、ベル研究所のデニス・リッチー(Dennis MacAlistair Ritchie)がUNIXオペレーティングシステムの開発中にC言語を創造しました。これはアセンブリ言語と比べて自然言語により近い言語であり、アセンブリ言語よりも可読性に優れています。
以下は、Hello Worldを出力する古典的なコードです。これはC言語開発を学ぶほぼ全員が経験する共通の第一歩です。
#include <stdio.h>
int main() {
printf("Hello, World!\n");
return 0;
}この5行は、一つの仕事を完了します:コンソールにテキスト文字列を出力する。
これは簡単なことだと思う人もいるかもしれません。C言語はこれだけであり、大した意義はないと考えるなら、それは大きな間違いです。同じ機能をアセンブリ言語で実装したものを見てみましょう:
data segment ;データセグメント
string db 'Hello,World!$'
data ends
code segment ;コードセグメント
assume cs:code,ds:data
start:
mov ax,data ;セグメントベースアドレスを取得
mov ds,ax ;レジスタにセグメントベースアドレスを送入
mov dx,offset string
mov ah,9
int 21h
mov ah,4ch
int 21h
code ends
end startこのようなアセンブリコードを書くには、少なくとも以下の知識が必要です:レジスタの概念、コードセグメントとは何か、データセグメントとは何か、ベースアドレスとは何か、アセンブリの多くの構文。ほとんどのアセンブリ言語の教科書は50ページ以上を費やしても、外部ソフトウェアの助けがなければソフトウェアレベルで効果を少しも見ることができません。C言語は明らかにはるかに優れています。
C言語のあの数行に対して、ほとんどのチュートリアルは千字を超えることはほとんどありません:ヘッダファイルとは何か、メイン関数とは何か、これらの概念は非常に簡単で、説明すれば理解できます。
したがって、C言語の利点は以下の通りです:
- ハードウェアレベルではなくソフトウェアレベルから出発し、学習コストを削減
- 多数の操作をネイティブサポートし、記述を簡素化し、読みやすくする
もちろん、欠点もあります。gcc -S -masm=intel m.c -o m.sコマンドを使ってプログラムをコンパイルすると、コンパイラがCコードを以下のような内容に翻訳しているのがわかります:
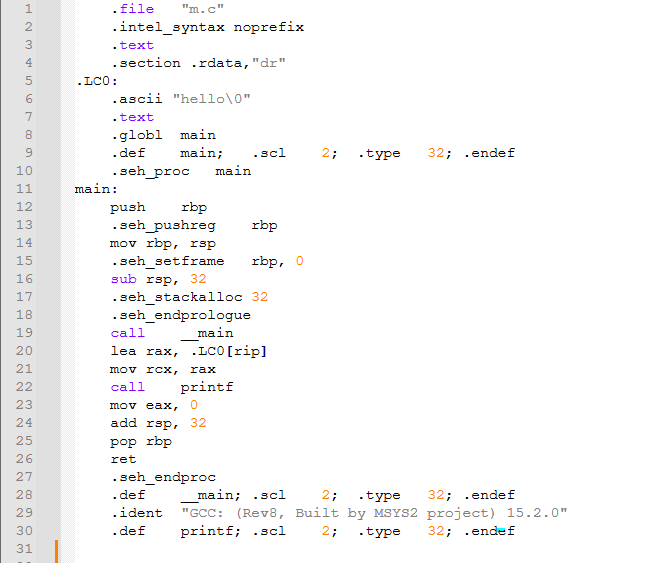
合計30行です。では、通常の書き方で同等のアセンブリコードを書いてみましょう(出力内容に語が一つ追加されていますが要点には影響しません):
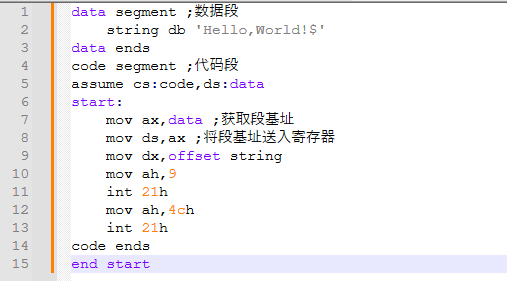
純粋なアセンブリのバージョンは15行しか使用していません。つまり、コンパイラは同じ効果を実現するために倍書いたことになります。実際、この差異はコンパイルの後期段階でより顕著になります。通常のGCCコンパイルプログラムはリンク段階でいくつかのライブラリファイルをリンクする必要があり、最終的な生成物は純粋なアセンブリよりも数十倍大きくなる可能性さえあります。
これがC言語の欠点です。過程における「少ない記述」と引き換えに、結果において「多い記述」を使用しています。その理由は結局のところテンプレート化にあります。ここでの出力を例にとると、出力したい内容はテキストであり、printf関数を使用します。しかし、この関数は整数や浮動小数点数なども出力できます。普遍性を確保するために、コンパイラは他のデータ型に適合するコードもコンパイル後のファイルに書き込まざるを得ませんが、実際には使用しない機能もあるでしょう。
tips:筆者は実際のところCにはあまり好感を持っていません。メモリリークの問題はさておき、手続き型言語そのものがそれほど便利ではないからです。時々C++でソフトウェアを書くのにCの構文を使わざるを得なくなり、正直言って、本当に面倒です(現在のGCCコンパイラでさえまだC++で書かれていると聞きました、なかなかおかしいです)。
2. C++の新生
C言語は確かに強力ですが、それは人々がすでにC言語の開発効率に満足していたことを意味するわけではありません。C言語には依然としていくつか不尽意(不十分)な点がありました:C言語は手続き型言語であり、コードの再利用率が不十分です。自身の設計上の問題により、危険な型変換や様々なエラーが発生しやすく、メモリリークのリスクも高いです。開発過程では、C言語のエラー報告機制は完全ではなく、万行のコード内でしか安定した実行を保証できません。
したがって、1983年、C++が出現しました。デンマークのビャーネ・ストロヴストルップ(Bjarne Stroustrup)教授がC言語を基にクラスなどの概念を追加し、所謂「オブジェクト指向プログラミングをサポートする」C++を創造しました。この言語はメモリリーク率を著しく低下させ、百万行規模の大規模プロジェクトにも対応しました。
C++の出現は間違いなく画期的な出来事でした。その出現に伴い、多態性、カプセル化、オブジェクト、継承、名前空間、仮想関数、テンプレートなどの概念が急速に流行し、後の言語(Javaなど)にも多かれ少なかれ影響を与え、言語の抽象化能力を最重要視するようになりました。
以下はC++のいくつかの機能のデモンストレーションです:
class Person {
public:
virtual void SenRen_BanKa() = 0;
};
class DiYongJie : public Person {
public:
std::string play = "YuZu soft!"
void SenRen_BanKa() override {
std::cout << "Ciallo!" << std::endl;
}
};多くの概念が追加されましたが、C++とC言語は依然として強く関連しています。C言語のコードについては、C++は基本的に互換性があります(ただし古いヘッダファイルは確実に置き換える必要があります)。両方の言語は実際非常に似ています:
#include<iostream>
using namespace std;
int main(){
cout<<"Hello World";
return 0;
}この保持と進化の共存により、C++は急速に成功し、大規模ソフトウェア開発が可能になりました。今日でもゲームエンジン、オペレーティングシステムなどの高性能分野で広く応用されています。
3. 特徴比較
| 特性 | C | C++ |
|---|---|---|
| プログラミングパラダイム | 手続き型 | マルチパラダイム |
| メモリ管理 | 手動 | 手動 + スマートポインタ |
| 標準ライブラリのサイズ | 最小 | 巨大 |
| 名前空間管理 | 欠如 | 完全 |
| ヘッダファイル包含機構 | 原始的 | 改良済み |
| アプリケーションシナリオ | 組み込みシステム | 大規模商業ソフトウェア |
tips:C++は多くのCスタイルの操作を保持しながら優れた便利な標準ライブラリを追加したため、算法界では時々「C with STL」と冗談交じりに呼ばれることさえあります。
五. Java:クロスプラットフォームの夢の実現
高級言語が誕生してしばらく後、インターネットが蓬勃に発展(急成長)しました。しかし当時は、静的ページを表示するためにHTMLのようなマークアップ言語だけに依存していました。そのため、当時インターネットにアクセスすることは、実質的にはオンラインのWord文書を閲覧することであり、これはインターネットの可能性を大幅に制限しました。人々はすぐにこれに気づき、ウェブサイトを動的にする手段を探し求めていました。しかし、初期の言語はデバイスに対する要求が非常に特化しており、コンピュータソフトウェアは決して(絶対に)マイコンなどのハードウェア上では実行できませんでした。そのため、探求の方向は、クロスプラットフォーム伝播能力を持つソフトウェアを開発する技術を持つことになりました。
このような背景の中で、Sun MicrosystemsはJava言語を発表し、「Write Once, Run Anywhere」(一度書けば、どこでも実行)という革命的な理念(コンセプト)を伴って登場しました。発表されるとすぐに急速に成功しました。1996年1月、Sunは最初のJava Development Kit(JDK 1.0)をリリースし、Javaが独立した開発ツールとなったことを示しました。わずか8か月後、約8万3千のウェブページがJava技術を応用していました。
以下はJavaのコードです:
public class Main {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}実際、Javaは依然としてC/C++の多くの考え方を保持しています。なぜなら、それ自体がSun Microsystemsによって開発されたOak言語から発展したものであり、Oak言語はSunがマイコンプログラムを開発するために作成した簡略化されたC++だからです。
Javaは設計当初から消費者向け家電製品ソフトウェアの開発を目的としていたため、「信頼性」に対して多くの最適化が行われました。したがって、Javaには以下の利点があります:
- C/C++から進化したため、習得が容易で、構文がより簡潔
- ポインタという概念を削除した。ハードウェアは開発者にとってほとんど完全なブラックボックスとなり、ソフトウェアの安全性を保証すると同時に学習コストを削減
- 高い移植性
これらの利点により、Javaはエンタープライズ級アプリケーション開発で主導的立場を占め、Android開発の基礎言語の一つとなりました。しかし、移植性のためにもたらされた性能上の損失もあり、高性能計算シナリオには適していません。
tips:Javaは冗長で有名で、多くのプログラマーからからかわれる点です。正直なところ、私のJavaに対する初期の印象は「C++のクラスを単独で引き出した」というものでした。
六. Python:簡潔さの哲学の勝利
1. 簡潔な構文
1989年、グイド・ヴァンロッサム(Guido van Rossum)によって設計されたPythonは、コードの可読性を極限まで推し進めました。自然言語に極めて近い構文を使用することで、Pythonの習得難易度は大幅に減少し、大量のプログラミング初心者が殺到して学びました。
以下は、PythonでHello Worldを出力するサンプルプログラムです:
print("Hello World")わずか一行で、Pythonは出力を完了できます。これはその大きな特色の一つを体现しています:簡潔さ。Pythonはそれ以前の言語のいくつかの冗長な内容を簡略化し、開発者が機能の実装ではなく本当のアルゴリズムに集中できるようにしました。
2. 強力な標準ライブラリ
PythonをC++と比較すると、争う事実は、C++のint型変数は-2,147,483,648~2,147,483,647の間の内容しか保存できず、最も長いlong long型変数でさえ、-9,223,372,036,854,775,808~9,223,372,036,854,775,807の内容しか表現できないのに対し、Pythonのint変数にはいかなる制限もなく、オーバーフローすることなく任意の大きさのデータを保存できることです。
上記の差異を実際の開発に当てはめて、C++とPythonの高精度計算を比較すると理解できます。算法プラットフォーム洛谷には一道题目(一つの問題)があります:1からnまでの階乗の和を求めるものです。Pythonの解答を見てみましょう:
n=int(input())
ans=0 #最終答案存储 (最終答えの保存)
rec=1 #阶乘累加的变量 (階乗を累積する変数)
for i in range(1,n+1):
rec*=i
ans+=rec
print(ans)数行で搞定(解決)しました。とても簡単な問題ですよね?
しかし、洛谷で標示されている難易度は比較的高いままです。なぜでしょうか?以下のC++コードを見ればわかります:
... (長いC++コードのため省略) ...C++でこの問題を書くのは異常に長いです。これは、この問題のデータ計算結果が非常に長くなるため、C++は結果のオーバーフローを防ぐためにシミュレーションアルゴリズムを使用する必要があるからです。一方、Pythonには元々シミュレーション機構が組み込まれており、ユーザーが自分で書く必要はありません。
Pythonの利点
定義上、Pythonはインタプリタ型言語であり、Javaと同じ柔軟性と高い移植性を持っています。そしてスクリプト言語として、Pythonはデータ計算などの自動化作業により長けているため、大規模言語モデル、ウェブクローラーなどで広く応用されています。
Pythonの利点は以下の通りです:
- 標準ライブラリが強力で、操作が簡潔
- オープンソースコミュニティが継続的に維護(メンテナンス)されている
- サードパーティ製ライブラリが豊富
- インタプリタ型言語のため、デバッグ時間の節約
tips:ここ数年、Pythonを一无是处(全く役に立たない)と非難する人々がいます。インタプリタ型言語は実行效率(実行効率)が奇低(異常に低い)と考えています。私は各有各的好处(それぞれに利点がある)と言うしかありません。例えば、Pythonは情報技術の必修1の段階でTKというウィンドウライブラリを教えることができますが、C++はMSDNの中で自分で摸爬滾打(這いずり回って苦労する)しなければ文档(ドキュメント)を見つけられません(実体験)。
七. 中国語インターネットにおける探求
1. 易语言(Easy Language)
プログラミング言語は発展を続け、中国にも及びました。2000年、中国語プログラミング言語が横空出世(突然現れ)ました。表計算プログラミングを採用し、同樣に解释运行(インタプリタ実行)され、簡単な中国語を使用してソフトウェア開発を行います。これが易语言です:
.如果(もし)(用户输入(ユーザー入力)=="你好(こんにちは)")
输出框(出力ボックス).显示(表示)("你好,世界!(こんにちは、世界!)")
.否则(そうでなければ)
输出框(出力ボックス).显示(表示)("无法识别(認識できません)")他のプログラミング言語とは異なり、易语言の第一课(最初のレッスン)は直接ウィンドウの開発です。软件开发周期(ソフトウェア開発サイクル)が短く、中文学习编程难度(中国語でプログラミングを学ぶ難易度)が低いため、一瞬间(一瞬)で多くの人々を引き付けました。
以下は易语言のコード記述ページのスクリーンショットです:

易语言の利点は以下の通りです:
- 英語の壁を低くする
- 開発を简化(簡素化)し、開発效率(効率)を加速する
- 强力的な官方组件(強力な公式コンポーネント)、各方面の内容(あらゆる側面の内容)をカバー
欠点もあります:
- Windowsプラットフォームに限定される
- オープンソースエコシステムが欠如している
- 32ビット编译(コンパイル)のみサポートであり、运行效率(実行効率)が不足している
2. 文言(Wenyan-lang)
易语言の後、中国語プログラミングは一時的に興隆しました。2019年には、文言(Wenyan-lang)という名前のプログラミング言語が再び興りました。
名前が示す通り、文言は文言文(古典中国語)を使用してプログラムを書くため、それはほとんど一種の芸術形態となり、プログラミングツールではなくなりました:
吾有一數。曰三。名之曰「甲」。
為是「甲」遍。
吾有一言。曰「「問天地好在。」」。書之。
云云。文言プログラミング言語は一種の実験的な言語であり、文言文化とコンピュータ文化を传播(広める)ために使用されます。Chicken言語、///、Glass言語、Piet言語などと同様に、一種の半藝術品(セミアート作品)であり、これはプログラミング言語の高度な発展を示しており、人々がある程度の創造性と芸術性を持つ分野の探求を考慮し始めるきっかけとなりました。
tips:易语言は筆者が最初に接触したプログラミング言語です。これは間違いなく「初心者に優しい言語」です。なぜなら、あまりにも便利だからです。グラフィカルインターフェース下でウィンドウ設計を完了できるため、すべてのチュートリアルの第一课はウィンドウから講義を始めます。正にこのため、私は後に他の言語のGUI作成が極めて面倒だと感じるようになりました。
八. 総括:発展の法則
上記のいくつかの例から、言語の変化の特徴を見ることができます:
抽象化レベルの向上 プログラミング言語は不断に「抽象化」に向かって発展し、コードの再利用率が逐渐に向上し、開発効率の向上を可能にします。 进化方式(進化の方法):機械命令 → 記号化 → 構造化 → オブジェクト指向 → 関数型プログラミング
效率(効率)のバランスの進化 開発者たちは、開発と使用のどちらが重要かについてより喜んで議論するようになりました。 进化方式:実行效率優先 → 開発效率優先 → 両者の動的バランス
領域特化 各領域で专门性的な言語(専門的な言語)が出現しました。典型的な例は、Windowsシステム下的
.rcファイル、Inno Setupの専用インストーラパッケージ記述言語などです。 进化方式:汎用言語 → ドメイン固有言語(DSL)構文の簡素化 进化方式:冗長な構文 → 簡潔な表現 → 自然言語への接近(第五世代プログラミング言語の探求方向)
九. 選択に関する提案
私たちの研究は、プログラミング言語が各有所长(それぞれ長所がある)と結論付けています。言語の選択は、自身のニーズに応じて合理的に組み合わせ、開発効率とアプリケーションシナリオを考慮して行うべきです。以下にいくつか推奨される組み合わせ方案を示します。
低水準開発
- 推奨:C / Rust / 少量のアセンブリ
- シナリオ:オペレーティングシステム、組み込みシステム
- 利点:ハードウェアに近く、多种の形態(多种の形態)にコンパイル可能
迅速な開発
- 推奨:Python / JavaScript / 少量のshell / 易语言
- シナリオ:Webアプリケーション、データ分析
- 利点:既成の関数、効率的な開発
クロスプラットフォーム要件
- 推奨:Java / Kotlin / QTフレームワーク
- シナリオ:エンタープライズ級アプリケーション、モバイル開発
- 利点:クロスプラットフォーム、移植性が良い
学術研究
- 推奨:Python / Julia
- シナリオ:科学技術計算、機械学習
- 利点:コードを简化(簡素化)、コードを書くことが負担にならないようにする
興味駆動
- 試す:文言 / 易语言
- 価値:プログラミングの本質を理解し、計算思维(計算論的思考)を育成する
プログラミング言語を選択する際、以下の内容が关键考量维度(重要な考察次元)です:
- プロジェクトの性能要求:高性能要件には断じて高級言語を選ばず、専門的计算(計算)にはなるべく低級言語を選ばない。
- チームの技術スタック现状(現状):チームメンバーのスキルに基づいて決定する。
- コミュニティエコシステムの成熟度:コミュニティは開発の支柱です。Rustコミュニティは典型的な案例(ケース)です。良好で成熟したコミュニティは、常にどこでもすべての開発者を助けることができます。
- 個人の学習曲線:個人の学習計画に基づいて選択する。
十. 後書き
このテーマは、私がずっと以前から研究を始めたかったものです。今回の研究性学習によって実現でき、自是无比兴奋(もちろんこの上なく興奮しています)。そのため、忙前忙后(前後に忙しく)多くのことをしましたが、確かに少し混乱も追加しました。
文档の编写者(文書の編著者)として、私は组长(リーダー)のように深厚な专业素养(深い専門的素養)や、一つの研究方向に専念する钻劲(集中力)を持っていません。不精(熟達していない)な知識と自ら尚可(まだまあまあ)と称する文学的水平(文章力)を借りて、これらの最终呈现的文字(最終的に提示された文章)を苟且(やむを得ず)書きました。终究(結局)少し惶恐(恐れ多い)であり、書かれた内容に欠陥があるのではないかと心配しています。読者の各位が記事中の誤りを発見されたならば、大小に関わらず、どうかGitHubのIssueで提交(提出)していただければ幸いです。
十一. 再版随笔(随想)
言語というもの自体が争议(論争)に満ちています。绝对的な正しいとか間違いとか良いとか悪いとかはありません。phpが多くのプログラマーによって「世界上最好的语言」(世界で最高の言語)と皮肉られているように、結局は広く使用されています。どんな言語であれ、自分に适合(合う)さえすれば、それは良い言語です。
少し前に、C++とPythonの対話というジョークを見ました。以下に大致(おおむね)記録します。
C++がPythonに「あなたの名前は何ですか」と尋ね、Pythonは答えません。C++は自分が礼儀正しくないと思い、自己紹介を始めます。しかし、自分の名前を言おうとしたところで行き詰まります。スタックエラーが発生したため、エラーを報告しながら去らざるを得ません。C++が遠くへ行ってしまった後、Pythonはようやく叫びます:「Python!」
このジョークは、C++が書きにくく、いつもエラーやクラッシュを起こすのに対し、Pythonの反応はとても遅く、C++が何百行もコードを実行し終わってもまだ入口にいるかもしれない、と言いたいのです。このジョークがうまい点は、C++とPythonの欠点を同時に阐明(明らかに)していること、つまり、完璧な言語は存在しないという概念を伝えていることです。
参考文献
- 川合秀实『30日でできる!OS自作入門』| 人民郵電出版社
- プログラミング言語発展簡史
- プログラマーとして知っておくべきプログラミング言語年代記
- 王爽『アセンブリ言語』| 清華大学出版社
- 百度百科-アセンブリ言語
- 百度百科-ニーモニック
- Deep Learning - Ian Goodfellow、Yoshua Bengio、Aaron Courville
- 黒馬程序员『Webデザインと制作プロジェクト教程』(第2版) | 人民郵電出版社
- 機械から知能へ:アセンブリ言語の過去、現在、未来
- 洛谷-P1009-階乗之和
- Java
- 張毅剛、趙光权、劉旺『単片機原理及応用』第三版 | 高等教育出版社
- 郭衛斌、羅勇軍『算法競賽入門到進階』 | 清華大学出版社
- MSDN - Microsoft Learn
- C++、C およびアセンブラー\C++ 構文リファレンス
- C++ reference
- 汪楚奇『深入浅出程序設計競賽』 | 高等教育出版社
- 郁紅英、王磊、武磊、李春強『計算機操作系統』(第三版) | 清華大学出版社
声明
文中の「機械語」セクションにおいて、機械語コードはアセンブリコードをOnline x86 and x64 Intel Instruction Assemblerで変換したものです。変換に問題があるかどうか不确定(不確実)であるため、参考価値はなく、機械語の不便さを辅助理解(理解を助ける)するためにのみ使用されています。